Figure 2 shows labelling being applied at several different stages during the manufacturing process and throughout the supply chain. Typically, this would encompass blister packs, cartons, shipper cases, marketing materials and all forms of electronic labelling.
Viewing this from another angle, each region, country, provider and patient may require content that is unique. Again, with a preconfigured set of rules, the rules engine enables a product destined for a specific group of patients and serviced by a particular provider to have certain fields on its associated label automatically populated.
Alternatively, or in addition to the above, the rules engine can either add or suppress fields presented to the labelling user to ensure the correct information is captured.
Typical applications
As discussed previously, every element that can appear on a label (whether in printed or electronic format) can be considered to be a “fact.” In the context of labelling, such facts could relate to branding, regulatory statements, product information, etc., and can be both text and symbols. The rules engine itself can then act upon these facts in one of several ways.
Autopopulation of data: It is not untypical for labelling and artwork software vendors to provide maximum possible flexibility at each stage of the process, making all fields and options that might be needed for each type of label available to the user, irrespective of their role and task at hand.
Although this provides a large degree of flexibility and accommodates the needs of every potential user and type of label, it has several downsides. First, it may need the user to decide which is outside the scope of their role or sphere of knowledge. Secondly, it could lead the user to guess at what is being asked for.
Thirdly, the field could simply be left blank. The likely outcome being labelling errors and missing information. This is especially critical when such fields relate to market-specific legislative requirements.
A good example of this might be when a product sold into a certain market requires a particular symbol or statement to be included on a “front label” in a specific position. By specifying the country and product type, the rules engine will determine which fact (symbol or statement) needs to be included where and subsequently autopopulate the label template.
In less complex situations, when field values remain constant across multiple instances of labels, autopopulation can eradicate many of the mundane repetitive tasks that can otherwise lead to the introduction of errors through fatigue and distraction.
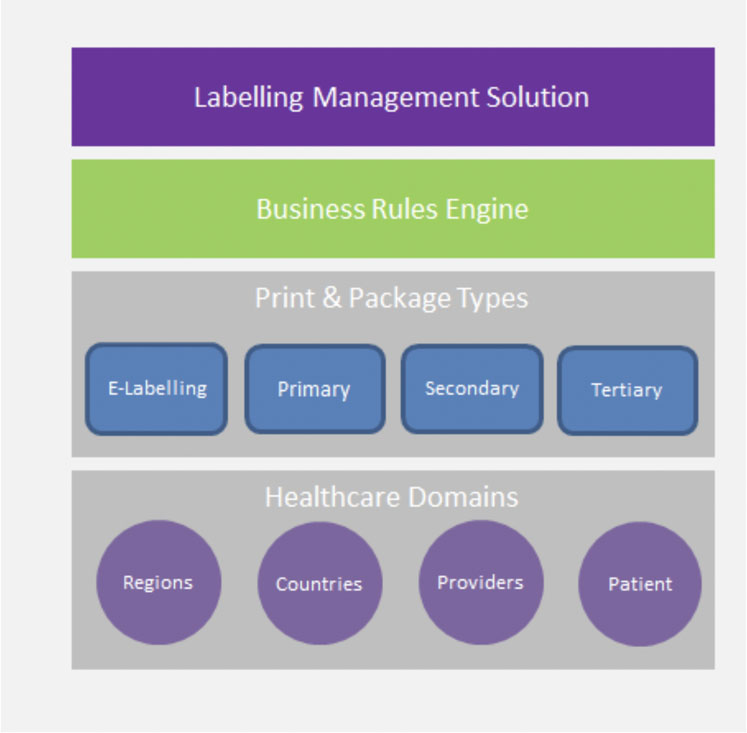
Figure 2: Applying a business rules engine to labelling
Metadata manipulation: An example of metadata manipulation might be ingesting an abbreviated product name from SAP and transforming it to the correct labelling content. In a slightly different context, some labels may need additional content added that is not otherwise included. Without the labelling and artwork system having in-built intelligence to prompt the user that he/she needs to select and add additional content, the need for this may get overlooked.
An example might be when a product sold into a certain market requires an additional field added to meet local safety legislation (which might be termed a “mandatory field”). In this case, given a predetermined rule triggered by a specific product code, the rules engine would automatically present this field to the user for content to be added.
In some instances, it may also be possible to prepopulate such a field by using an “autopopulation rule.” This metadata manipulation can also be applied to remove as well as add fields, such as when a normally required phrase or symbol may not be relevant to either the product type or the market into which it will be sold.
View adaptation: One of the most often heard complaints from the labelling and artwork user community is that they are tasked with trawling through screens of prompts without any guidance regarding which fields need to be populated in relation to their role and responsibilities.
Here, a rules engine can also modify the interface presented to the user based on their role such that he/she only sees relevant fields and not the full scope of options that may or may not be relevant. Furthermore, not all fields will be relevant to all regions or locales.
In some cases, a subset or superset of fields may be required depending on local regulatory requirements. For example, local in-country affiliates may only see the fields that need to be populated with local regulatory statements or symbology, whereas those in marketing and regulatory may be given a broader (and possibly different) selection of fields to populate. This vastly simplifies the role of each stakeholder called on to input content and reduces the risk of omissions and errors.
PLM works order manipulation
Many large organisations have implemented product lifecycle management (PLM) software to underpin their product design and manufacturing processes. Therefore, much of the “standard” content (product name, ingredients, instructions, etc.) can reside in these systems. It may be stored in a truncated form or possibly codified to support machine-to-machine communication with other business applications.
Although a selection of this data will be needed for product and package labelling (including electronic labelling), it is not always in the structure and format required for printing directly onto each type of label.
Working through this example, the PLM system may have truncated one or more attributes associated with the product that may need to appear on the label — a typical example being product name. Alternatively, the PLM system may generate a product code that may need to be transformed into a product name.
Inserting a rules engine at this point can automatically translate from what could be termed “unstructured data” to content that is “labelling ready,” saving significant effort and potential rework.
Which rules engine?
Organisations wishing to deploy a rules engine can choose from a number of different options, including both open source and commercial offerings. Rather than describe the pros and cons of various types of rules engines and attempting a comparison, we will look at some of the criteria to consider when making such a decision in the context of labelling and artwork.
Rules engine selection criteria: Listed below are a number of factors that may be worth considering when evaluating a suitable rules engine to simplify your labelling and artwork processes:
- Domain specialism: although there are a number of both open source and commercial off-the-shelf rules engine products available, it’s worth considering the extent to which these will satisfy some of the unique requirements that labelling and artwork tasks often present
- Configurable rules: to what extent are the rules configurable to satisfy the needs of your organisation, users, markets and products?
- Dynamic rule application: will the rules engine allow you to dynamically create and update a range of label types (primary, secondary and factory printed labels) from a single request?
- Rules admin: how easy is it to create the rules and collate these to create rule sets and then apply certain rule sets across different operating regions (Europe, North America, Asia, etc.)? Some rules engines provide a business user interface to enable more competent users to configure and apply the rules themselves
- Rules execution: does the rules engine perform validation of any transformations wherein data entered within the system generates a match to a symbol or phrase that doesn’t exist in the system and therefore requires an entry into the audit log?
- Batch upload: as much of the data populated within labelling and artwork systems is derived from external sources, having a rules engine that can execute rules during any batch upload process can save time, cost and improve quality
- Flexible configuration: although the rules engine should offer sufficient flexibility to address the wide scope of conditions and exceptions discussed in this paper, it should also allow for a base view to be created (for the fields that will always be present across all labels) with a set of standard fields
- Trigger points: flexibility to enable rules to be triggered and retriggered at multiple points during the data capture process if and when data changes during data collation process.
Summary
Considering the application of a business rules-led approach, we’ve considered a number of scenarios that are specific to the capture and collation of artwork content when a business rules engine could both simplify and derisk the overall process, making organisations leaner and more agile.
The feasibility of adopting a rules-based approach to labelling and artwork shows clear benefits. As organisations continue to grow, many acknowledge that satisfying increasingly stringent regulatory requirements plus meeting increased levels of user sophistication will be challenging using manually driven processes.
The alternative of deploying rules into a standalone BRMS has also been considered; and, whereas this is possible, we feel that the semantic nature of artwork and labelling content is better served by an integrated onboard rules engine.
Part I of this article is available here.